Behavioral Planning
31 Aug 2018Planning for self-driving vehicles consists of route planning, behavioral planning and motion planning. Route planning picks sequence of road segments. Behavorial planner generates discrete motion goals (location, speed) adherence to rules of road. It specifies desired lane and speed. One local goal can be driving down this lane reaching location (x,y). Motion planner generates trajectory to reach local goal.
Route planning works on a weighted graph representation using Dijkastra or A* search. There are efficient algorithms to handle large networks using precaching. Motion planning can use lattice planner, eg anytime dynamic A* for unstructured road eg parking lot. There are also sampling based approaches eg PRM, RRT etc. For lane driving, spline fit can be used. Numerical optimization with motion model as constraints can be used to optimize for safety and comfort. Trajectory must be checked against dynamic obstacles for collision. This blog post is mainly about behavioral planning.
CMU Boss
Paper “Autonomous Driving in Urban Environments: Boss and the Urban Challenge”, Christopher Urmson, Joshua Anhalt, Hong Bae, J. Andrew (Drew) Bagnell, Christopher R. Baker, Robert E. Bittner, Thomas Brown, M. N. Clark, Michael Darms, Daniel Demitrish, John M. Dolan, David Duggins, David Ferguson, Tugrul Galatali, Christopher M. Geyer, Michele Gittleman, Sam Harbaugh, Martial Hebert, Thomas Howard, Sascha Kolski, Maxim Likhachev, Bakhtiar Litkouhi, Alonzo Kelly, Matthew McNaughton, Nick Miller, Jim Nickolaou, Kevin Peterson, Brian Pilnick, Raj Rajkumar, Paul Rybski, Varsha Sadekar, Bryan Salesky, Young-Woo Seo, Sanjiv Singh, Jarrod M. Snider, Joshua C. Struble, Anthony (Tony) Stentz, Michael Taylor, William (Red) L. Whittaker, Ziv Wolkowicki, Wende Zhang and Jason Ziglar. Journal Article, Carnegie Mellon University, Journal of Field Robotics Special Issue on the 2007 DARPA Urban Challenge, Part I, Vol. 25, No. 8, pp. 425-466, June, 2008
Behavioral planning must deals with dynamic context. The most basics ones include lane driving, intersection handling and achieving a zone pose. The CMU Boss was the winner of 2007 DARPA Urban Challenge, the planner is based on rules for each context. It also has a error recovery mechanism for out of context behavior, which also follows a set of well designed procedure to deal with failures.
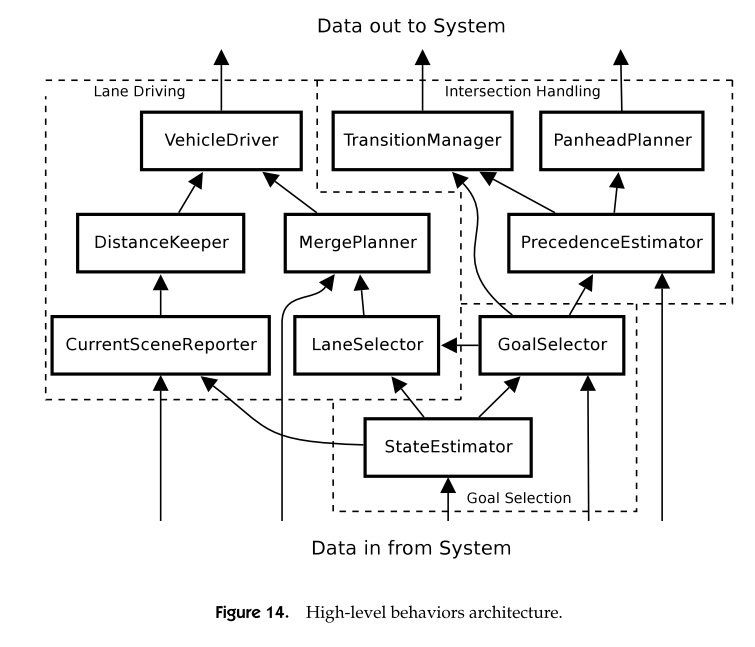
Intersection
The road model for the intersection include a set of exit waypoint, stop lines, virtual lane, yield lane, geometry of lanes. To handle stop sign, precedence is estimated by a occupancy polgon 3 meters in front of the stop lines. The arrival time of any car into such a polygone is ordered as the precedence.
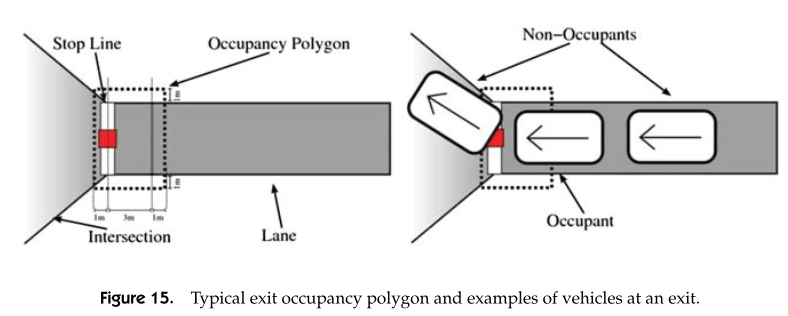
For a T intersection egovehicle should yield to both way of traffic. The condition for merging is calculated considering the velocity and distance of all other vehicles, and acceleration of egocar.
Lane
For lane follow, calclate acceleration and derised gap. For merge, the merge distance for boss is 12 meters. Determine front-merge or back-merge, check spacing, velocity, accerlation for possiblity of a merge. Paper gives formulas that consider acceleration to overtake, deceleration to merge in the back.
Error Recovery
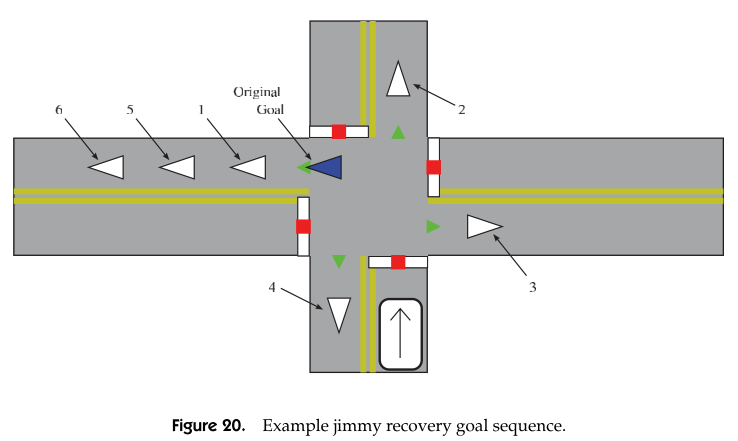
Error recovery is invoked when current goal is not able to met. There are sepearate procedures to follow to handle failures for on-road, intersection, zone. The rules are called shimmy, jimmy, shake and bake. For example these are the procedure to handle failures at an intersection:
- Treat goal as pose goal, a more powerful motion planner is invoked.
- Ask the router planner to try different route.
- Treat further points along the original route as pose goal.
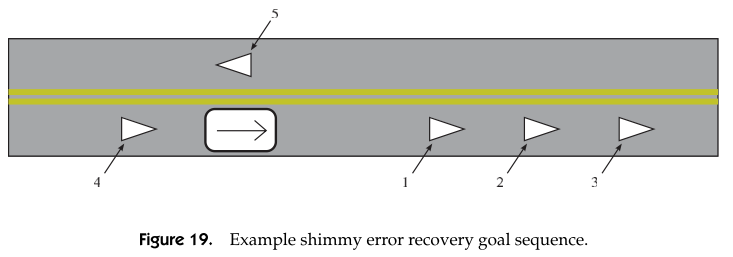
The lane driving error recovery can be triggered when small obstacle blocks part of the signle lane road, the recovery follows these procedures
- Try further goals down the road 20 meters at goal 1, 2 and 3 are then 10 meters apart. This will promopt the motion planner to plan around obstacle possible into the income traffic lane if possible.
- Backup to goal 4 and retry further goals down the road.
- Try a U turn goal 5.
- If this is one way road, try goals further than 40 meters and no long requires to stay near the lane, so that motion planner can wander arbitrary to go forward.
Multiple Policy Decision Making
Enric Galceran and Alexander G. Cunningham and Ryan M. Eustice and Edwin Olson, “Multipolicy decision-making for autonomous driving via changepoint-based behavior prediction: Theory and experiment”, Journal of Robots, 2017.
Multipolicy Rollout
Boss planner assumes other vehicle keep current speed, therefore it does not consider complex interactions between vehicles. For example a change lane to the left is bad when another car has high probability to merge right into the same lane. This paper samples likely policies for all other vehicles and score all policy for the egocar by forward simulate to 10 seconds in the future, simulation step is 0.25 seconds. Use a manually designed reward function to score each egocar policy and choose the one with highest average reward. The reward function considers safety, comfort and progress. To limit the complexity, during the simulation a car won’t change its policy except it allows logical transition for example after merge left, follow lane is logical. This is an approximate POMDP solver.

Behavioral Prediction
The probability of a policy used for sampling depends on the vehicle history. Use CHAMP algorithm to compute the most likely history segments and associated policy and parameters. It is a HMM on the time of policy transition (equation 18, 19). Transition is model by a truncated gaussian over time, the policy evidence is the Gaussian deviation (equation 21) from the prescribed trajectory of that policy with a BIC penalty (equation 15).
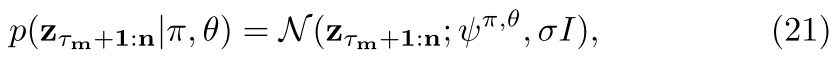
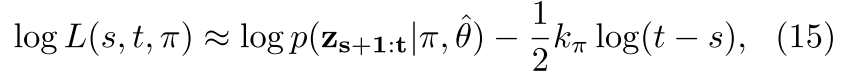
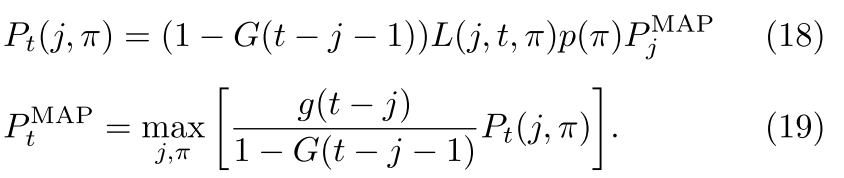
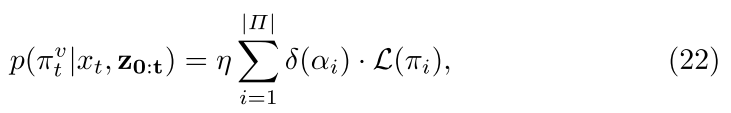
 The prediction for a vehicle of taking a policy right now is just the policy evidence over the most recent segment.
The prediction for a vehicle of taking a policy right now is just the policy evidence over the most recent segment.
The plicies are hand-engineered:
- Lane-nominal
- lane-change-right/lane-change-left
- turn-right, turn-left, go-straight, yield
The plicies can be extended to handle more driving requirements, eg adding merge-front and merge-back.
Intention Aware MOMDP Planner
Bandyopadhyay T., Won K.S., Frazzoli E., Hsu D., Lee W.S., Rus D. (2013) “Intention-Aware Motion Planning”. In: Frazzoli E., Lozano-Perez T., Roy N., Rus D. (eds) Algorithmic Foundations of Robotics X. Springer Tracts in Advanced Robotics, vol 86. Springer, Berlin, Heidelberg.
MOMDP
In MOMDP, mixed observability Markov decision process, only some variables are hidden to ecocar. It is a speical case of POMDP, while more efficient as the belief state only include the hidden variables. The goal of this paper is to solved the POMDP to find the optimal policy that maximize expected sum of reward given current state and belief of pedestrains’ intension. Approach in this paper is applicable to behavioral planning.
Offline planner construct a motion model for each agent intention. Robot solves momdp for a policy. online: execute policy over a set of intentions based on observed behavior. Robot only has an observation not the state of agents. agent has observes everything, it has its own policy conditioned on its intention. agent policy can be computed by MDP. Use SARSOP to compute the offline policy.
Pedestrian Intention Uncertainty at Crossing
This paper considers pedestrian’s intention as hidden variables. Their intension corresponds to goals only known to the pedestrian. Using MDP, a fixed policy is computed offline for pedestrain in order to get to goal quickly without collision with vehicle. This policy is followed by pedestrains online.
For example, paper compares with a Bayes-ML planner, which precompute mdp assuming known pedestrian goal, online bayesian inference picks the policy corresponds to the maximal likelihood estimation of the pedestrain intension based on observation. Figure 3 and 4 shows examples where MOMDP approach is superior. It uses 1mx1m grid, time step is 1 second. By considering the intention distribution, MOMDP won’t become falsely confident.
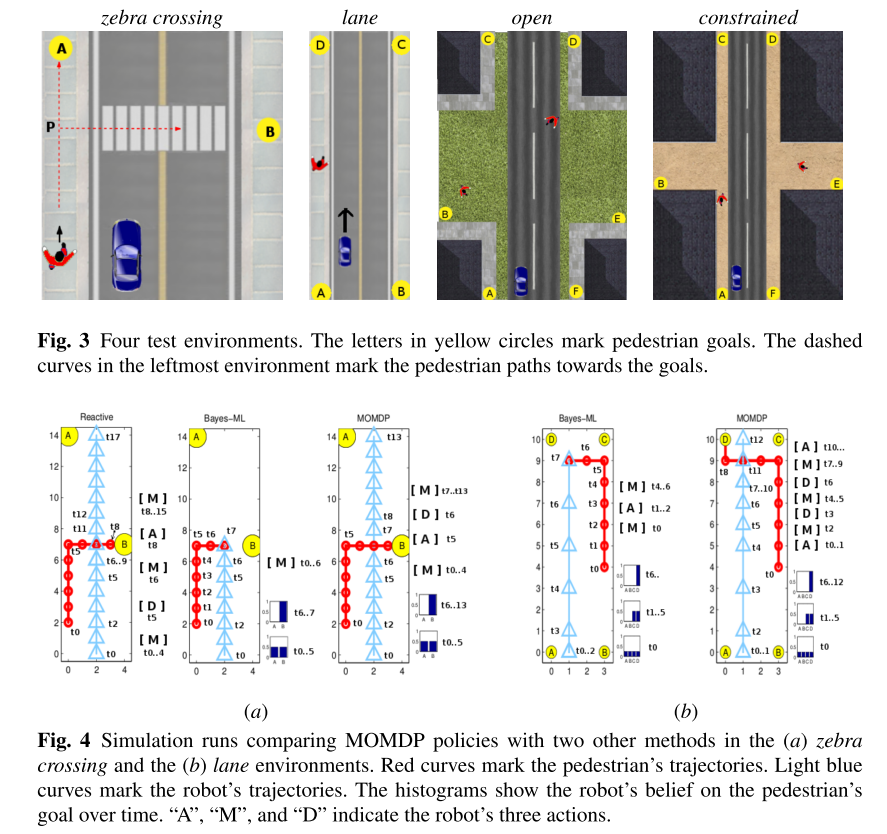
- In Fig 4.a for Zebra crossing, Bayes-ML cause accidents, because motion is noisy, at the crossing, if it believe the intention is slightly lower to cross, it will keep current speed and when it is clear peron is actually corssing, it is too late. robot choose accelerate in view of the possibility of accident. MOMDP resolves intention only when it is necessary.
- In Fig 4.b for lane crossing, pedestrian can cross the lane at any time, MOMDP planner considers both $C$ and $D$ equally likely, for safety, only when real intention is resolved, egocar decide to pass.
Driver Behaviors Uncertainty at Intersection
At an intersection, ecocar $R$ should respond to different aggressiveness of a car $A$ turnning left. This paper models 4 driving behaviors of another vehicle A.
- Oblivious. This driver increases his speed to 2 m/s and maintains it, totally ignoring the presence of other vehicles.
- Reasonable but distracted. This driver usually slows and stops before the intersection, but with probability 0.1, he may not stop.
- Impatient. This driver seeks to cross the intersection as fast as possible. He reacts to the speed of vehicle R, increasing his speed if R slows down and vice versa. He never comes to a complete stop at the intersection.
- Opportunistic. Similar to the impatient driver, this driver increases his speed if R slows down and vice versa. However, he will come to a complete stop at the intersection to avoid a collision.
Reward function tradeoff accident rate vs clearing time. The state of R consists of its position and velocity. Vehicle R receives observations on its own state and vehicle A’s state, but the observations may be noisy. The action is noisy with 5% of failing. Papers shows the accident rate of intention aware policy is very close to MDP with known driver intention. In this experiment, vehicle A is turning left. It is interesting that MOMDP can model other vehicles’ driving behaviros as hidden, and adjust action according to belief of aggressiveness of other vehicles.