3D Object Detection
08 Sep 2018Autonomous driving uses sensors to perceive the world around it. This blog considers two papers for 3d object detections using either Lidar or camera images. Lidar has depth information, but it is sparse. This makes 3d convolution inefficient. Image has dense semantics information, but it has occlusion issues, and depth information is not directly available. The 3D detection architecture is an extension of 2d approaches, such as faster-rcnn, thus they following the 3D proposal, then RoI pooling steps. The second paper has an interesting approach to fuse features from different sensors. The figures are blatantly copied from the original papers.
Monocular 3D Object Detection
Paper “Monocular 3D Object Detection for Autonomous Driving”, Xiaozhi Chen, Kaustav Kunku, Ziyu Zhang, Huimin Ma, Sanja Fidler, Raquel Urtasun, International Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
Use single image to estimate 3d objects. It generates 3D proposals by exhaustively placing 3D bounding boxes on the ground-plane. Assuming ground plane is orthgonal to the image plane and 1.65m down from the camera. With 3D bbox and a known camera, it is easy to project bbox to 2d image plane. The 2D image is segmented using pretrained SegNet model for pedestrian and cyclist. A separate instancde segmentation network is used for car image segmenation. After projecting 3d to 2D image, the proposals can be scored based on metrics such as the percentage of pixels belonging to the same class etc. The top ranked candidates are passed to a R-CNN like network to classify proposal, bbox regression and orientation regression.
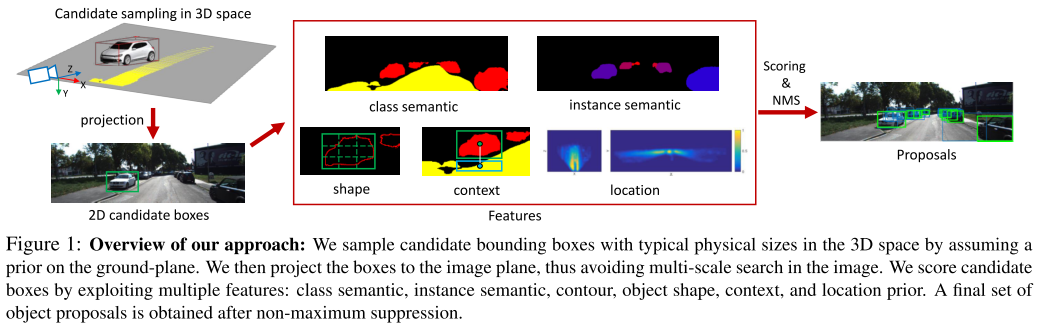
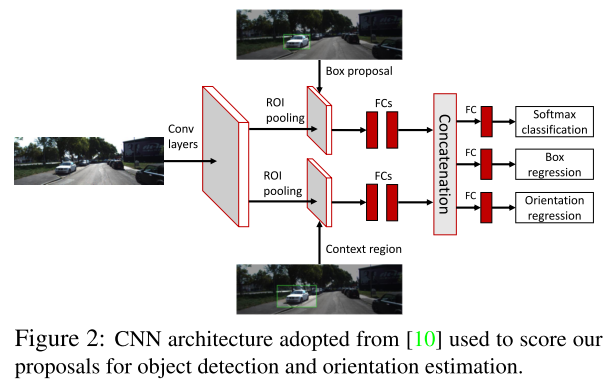
Use 0.2m voxel size to discretize 3D space. For an image, generate 14k candidate 3D boxes, reduce to 28% by heuristics such as removing a box if it only contains road pixels. The feature extraction through counting is fast due to using integral image in most of these counting. For Kitti object detection benchmark, AP get to 88% on cars, 66% on pedestrians, 66% cyclists on moderate data. Since monocular to 3D is a ill conditioned problem, larger but far away cars could be projected to the same shape as smaller but closer car. For safety reasons, I think a focused study on distance estimation will be interesting to see.
3D Object Detection with Lidar and Camera
Chen, X., Ma, H., Wan, J., Li, B., & Xia, T. (2016). Multi-View 3D Object Detection Network for Autonomous Driving. https://doi.org/10.1109/CVPR.2017.691
Similar to faster-rcnn, has a region proposal network and a RoI pooling network for classification/regression. Use both Lidar point cloud and image to compute 3D oriented bounding box for cars in Kitti dataset.

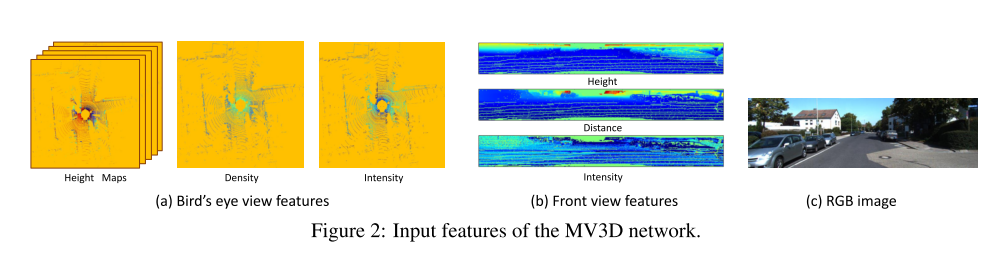
Use bird eye view and front view from 3d point cloud. The point could is trimed to only include points that are inside the image boundaries when projected to the image plane. The front view is using the cyclindal map. The x and y axises are the theta, phi angles of the lidar beams.
 Bird’s Eye View discretized into 2d grid with resolution of 0.1m. It has height maps, density and intensity. Intensity is the reflectance value of th epoint which has the maximum height in each cell. The density is normalized num of points in the cell. The height map has M slices, each slices has the max height of points in the cell.
Bird’s Eye View discretized into 2d grid with resolution of 0.1m. It has height maps, density and intensity. Intensity is the reflectance value of th epoint which has the maximum height in each cell. The density is normalized num of points in the cell. The height map has M slices, each slices has the max height of points in the cell.
Region proposal is on bird’s eye view, The 3D proposal for car is {(3.9, 1.6), (1, 0.6)}, height is 1.56m. To deal with small cars, the RPN does upsampling. The proposals are projected to the 3 views and use RoI pooling to get same size features. The three set of features are average layer by layers.
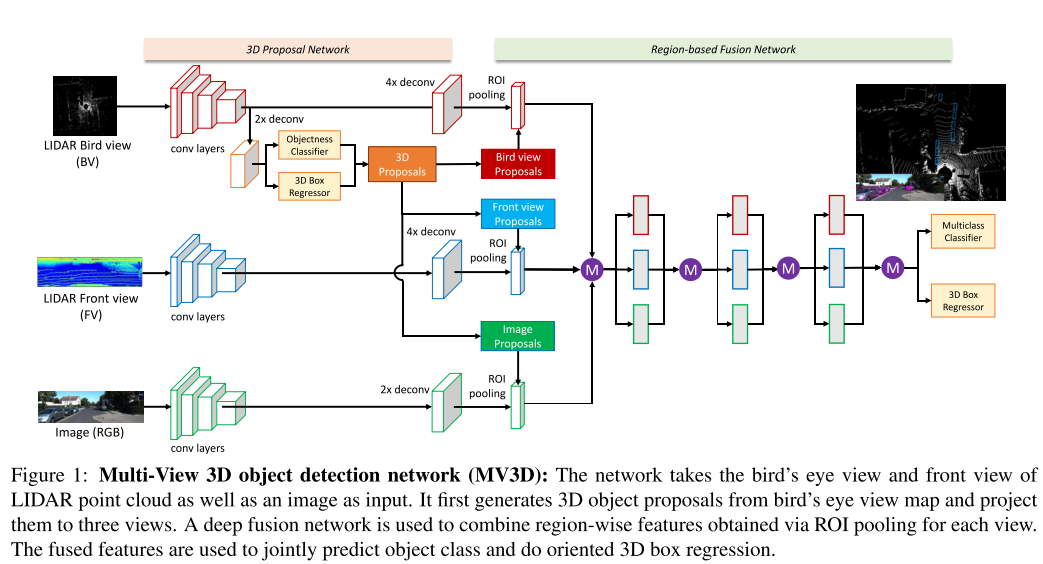 For training, does drop path regularization and add auxilaries goals for the three views.
For training, does drop path regularization and add auxilaries goals for the three views.
Lidar is good at 3d bbox, image is good at 2d bbox. The fused network is much better than the above Monocular image approach, and many lidar based approaches on Kitti for 3D localization and detection and 2D detection. The ablation studies show birds’ eye view is alone the best, followed by RGB, the worst one is front view alone.