Distibuted Systems in Industry
22 Sep 2018In this blog, we will look at several practical large scale distributed systems built esp for internet applications.
Facebook Graph Search
R. Nishtala, H. Fugal, S. Grimm, M. Kwiatkowski, H. Lee, H. C. Li, R. McElroy, M. Paleczny, D. Peek, P. Saab, D. Stafford, T. Tung, and V. Venkataramani. Scaling Memcache at Facebook. In Proceedings of the 10th USENIX conference on Networked Systems Design and Implementation, NSDI, 2013.
Nathan Bronson, Zach Amsden, George Cabrera, Prasad Chakka, Peter Dimov, Hui Ding, Jack Ferris, Anthony Giardullo, Sachin Kulkarni, Harry Li, Mark Marchukov, Dmitri Petrov, Lovro Puzar, Yee Jiun Song, Venkat Venkataramani. TAO: Facebook’s Distributed Data Store for the Social Graph. USENIX Annual Technical Conference 2013.
Twitter social graph database is called FlockDB, massively sharded mysql databases, stored both forward and backward edges. One challenge is super nodes for celebrities.
Challenge: large scale data, query and update.
MemCache
MemCache is demand-filled look-aside cache. A billion requests per second and storing trillions of items. Source can be mysql, hdfs and backend services (pregenerated results from ML). MySql replication across regions, invaliation generated from MySql commit log. Use remote marker, lease for best effort consistency. Use standalone pool for failures rather than rehashing.
single cluster. consistent hashing distribute keys. webserver all-to-all memcached servers. get is using UDP to avoid connection overhead, only 0.25% get are discarded. set and delete use TCP through mcrouter servers. Webserver threads share connection. For UDP each client has a request window for all servers similar to TCP to control congestion. Batching request by building a DAG. Issue lease (versioning) to cache miss to handle out of order updates, which also helps hot items. Create pools for different usage patterns. Handle small memcached machine failure by using a 1% idle pool instead of rehashing. optimizations: rebalance classes in slab allocator.
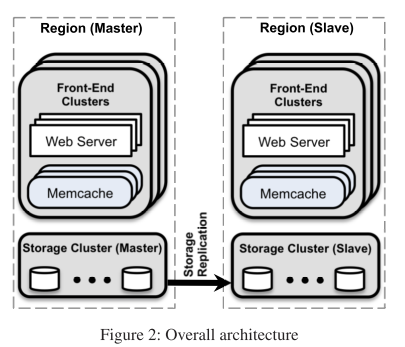
region: replicate multiple web/memcache clusters share same storage cluster. mysql commit log become batched invalidate messages, instead of webserver sending delete to other webservers.
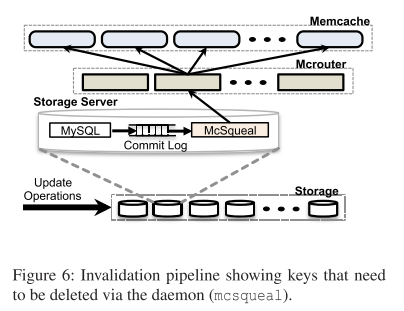
across region: geographic placement of data centers. Use mysql replication. One region is the master, handles write. lag. best-effort eventual consistency. The replicated mysql will send invalidation to memcache servers in any slave region. To avoid reading stale data in slave region, the write in the slave region will create a remote marker locally, subsequent read will be redirected to master region. Inter region communication is buffered.
Principles:
- Support monitoring, debugging
- Stay stateless
- Support roll out, rollback
- Simplicity
TAO Graph Service
why not memcache?
- store edge list
- logic is in each client
- read-after-write with master-slave replication
replace memcache, still based on mysql. tradeoff availability against consistency. API: objects and associations (stored at id1). many sharded MySql.
Unicorn social graph search
Not text search. But search enties and their relationships, like friend of friends of John, restaurants in SF likes by people living in beijing, people tagged in john’s photos.
(term, sort-key, id, HitData), sort-key and id is the DocId. serve from memory. Node is not just people, other things like pages, photos, likes. thousands of edge types. inverted index with posting list, eg people attened one university. Index sharding by result id instead of input terms, full list of hits for a given term often divided from all—index partitions. Operations eg friend:5 and gender:1, or friend:5 friend:6 (common friends ranked early).
Each index server has a immutable index and a small mutable index for addition/deletion. realtime update is via scribe tailer.
typeahead, use prefix of first and lastname to build postings to map it to userids. weakand, allow a term to be missing for upto x num of results.
scoring can consider HitData and forward index data (eg find people with similar age), heap based data structure to increase diverity not just based on score at aggregator. architecutre is top aggregator, verticles, each verticle has many replica, each replica has many racks, which has rack aggregator followed by indexer machines.
composite queries done by top aggregator: (apply tagged: friend:5), (apply friend: friend:5). Include lineage (edges to reach result) for privacy checks by the frontend.
Tail at Scale
distribute and gather amplify tail latency. approach: service differentiation, use time-slice to reduce blocking, synchronize background activity. Issue duplicate requests to replicas. Use micro-partitions to load balance. Use good enough result set, use canary for safety.
Bigtable
data model: (row:string, column:string, time:int64) -> string. single row read/write is atomic, regardless of columns. sorted by row key, partitioned into tablet. Data is stored in a format called SSTable, which is sorted and indexed (only index needs to be in memory). Master and many tablet servers. table is about 200MB, stored all data for a row range. There is a 3 layer b+-tree index for tablet location, it is cached in client.
Use Chubby for metadata about tablet servers and tablet location. tablet server has one memtable, many sstables, each are separately sorted, write is first write to a commit log, then applied to memtable. Read needs to merge info from all memtable and sstables. Periodic compaction merges sstables into one.
Single cluster is strong consistent, replication across regions are eventual consistent.
GFS
master and chunk servers, each chunk is stored as a linux file, replicated by 3. master has server info and file chunk info.
data mutation and atomic append. client push data to each replica, then ask primary to apply the mutation. The primary asks all replia to apply the change, so primary basically serialize the order of mutation.
NoSQL
https://medium.baqend.com/nosql-databases-a-survey-and-decision-guidance-ea7823a822d
data model: key-value store (hard for range query), document store, wide column store (column family in one disk)
consistency: